
1️⃣ L’auto-attention signifie-t-elle que l’IA comprend comme un humain ?
Non.
Elle calcule des relations statistiques entre tokens.
Il n’y a ni conscience, ni compréhension intentionnelle.
C’est de la mathématique appliquée à grande échelle.
2️⃣ Pourquoi est-ce plus puissant que les anciens modèles (RNN, LSTM) ?
Parce que :
- Tous les mots sont analysés en parallèle
- Les dépendances longues sont mieux captées
- L’architecture est scalable sur GPU
C’est ce qui a permis l’émergence des modèles Transformer en 2017.
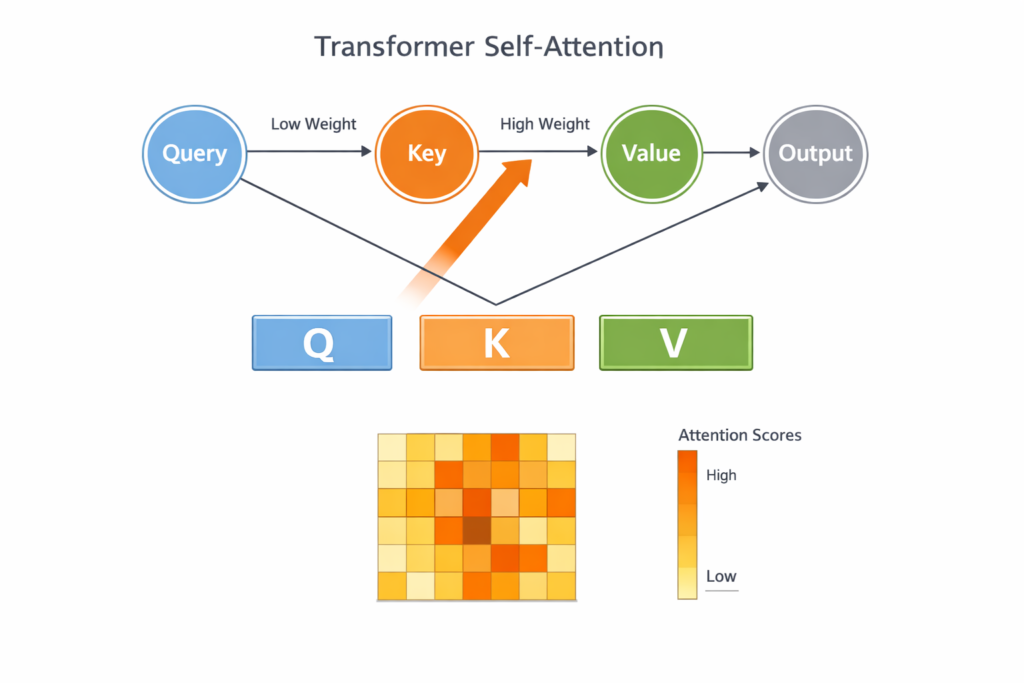
3️⃣ Pourquoi parle-t-on de “Query, Key, Value” ?
C’est une analogie issue des bases de données :
- Query : ce que le mot cherche
- Key : ce que les autres mots proposent
- Value : l’information réellement transmise
Le score d’attention dépend de la similarité entre Query et Key.
4️⃣ Pourquoi cela coûte-t-il cher en calcul ?
Parce que la complexité est en O(n²) :
Chaque mot est comparé à tous les autres.
Si une séquence contient 1 000 tokens →
On calcule 1 000 × 1 000 relations.
C’est pour cela que des variantes comme Flash Attention ont émergé en 2023-2025.
5️⃣ L’auto-attention fonctionne-t-elle uniquement pour le texte ?
Non.
On la retrouve dans :
- Vision Transformers (images)
- Modèles audio
- Modèles multimodaux texte + image + son
C’est devenu un standard transversal en IA.
6️⃣ Pourquoi est-ce important pour une PME ?
Parce que :
- Les assistants internes comprennent mieux les documents longs
- Les outils de résumé sont plus fiables
- La recherche sémantique est plus pertinente
- Les chatbots métiers gagnent en précision
7️⃣L’auto-attention explique-t-elle les hallucinations ?
Partiellement.
Elle structure le contexte, mais elle ne garantit pas la véracité des faits.
La qualité des données d’entraînement et le fine-tuning jouent un rôle clé.
8️⃣ Quelle est la limite actuelle ?
Même optimisée, l’attention complète devient coûteuse au-delà de très longs contextes (100k+ tokens).
Les modèles 2025 explorent :
- Attention linéaire
- Compression dynamique
- Mémoire externe



